Webinar Copilot mit Sebastian Schiller-Stoff, GPT-4o, Claude 3 in Europa

Liebe Liste, eine Erinnerung für das Webinar zu *GitHub Copilot*. *Sebastian Schiller-Stoff* wird zeigen, wie er Copilot in seiner täglichen Arbeit als Softwareentwickler einsetzt. * Morgen: 15.05. (11:30 bis 12:30) * Zoom: https://uni-graz.zoom.us/j/69588616456?pwd=OFJsYzc0TXFXM3draHI2M2ZGSDlSUT09 Und noch zwei interessante Infos: *Claude 3 ist nun auch in Europa verfügbar*: https://claude.ai Aber wahrscheinlich zu spät, denn OpenAI hat gestern *GPT-4o* veröffentlicht. Das ist nämlich kostenlos! Anbei ein kleines und schnelles Slide-Deck, wo ich alle Infos über GPT-4o gesammelt habe, soweit ich sie aufbereitet habe (#AISteward). Oder das AI Explained Video zum Thema: https://youtu.be/ZJbu3NEPJN0?si=52rDEQyVV-8ipyEb Kostenlos sind die Anfragen auf 16 alle 3 Stunden begrenzt (wenn ich das auf Discord richtig gelesen habe). Vision und Audio sind eigentlich ziemlich krass ... wenn ich das mal so "wissenschaftlich" ausdrücken darf. :) Liebe Grüße Christopher und Gerrit

Lieber Christopher, liebe alle, Danke auch für das update zu GPT4o. Mich hat da besonders der Punkt "Gute Texterzeugung in Bildern" interessiert, denn das war bisher ja eine doofe Schwäche. Und in deinem Beispiel auf der Folie ist ja auch korrekter Text. Jetzt habe ich das in GPT4o selbst getestet und kann das nicht bestätigen. Es macht zwar ein "Diagramm" mit korrektem Text, aber bei "Bildern" scheint es immer noch von DALL-E abhängig zu sein (?), das dann wieder alles verhunzt? Auf Rückfrage bestätigt GPT, dass das zweite von DALL-E gekommen sei und behauptet GPT, dass das erste python+matplotlib sei. Deshalb die Frage: wie wird wohl das Beispiel auf deiner Folie erzeugt worden sein? Das ist dann doch nicht DALL-E? Weiß jemand genaueres? Vermutlich ist es doch einfach DALL-E. Ich habe den Prompt für das Beispiel nochmal in einen frischen Chat kopiert und bekomme dieses wie üblich falsche Ergebnis: Viele Grüße, Patrick Am 14.05.2024 um 10:10 schrieb Christopher Pollin:
Liebe Liste,
eine Erinnerung für das Webinar zu *GitHub Copilot*. *Sebastian Schiller-Stoff* wird zeigen, wie er Copilot in seiner täglichen Arbeit als Softwareentwickler einsetzt.
* Morgen: 15.05. (11:30 bis 12:30) * Zoom: https://uni-graz.zoom.us/j/69588616456?pwd=OFJsYzc0TXFXM3draHI2M2ZGSDlSUT09
Und noch zwei interessante Infos:
*Claude 3 ist nun auch in Europa verfügbar*: https://claude.ai
Aber wahrscheinlich zu spät, denn OpenAI hat gestern *GPT-4o* veröffentlicht. Das ist nämlich kostenlos! Anbei ein kleines und schnelles Slide-Deck, wo ich alle Infos über GPT-4o gesammelt habe, soweit ich sie aufbereitet habe (#AISteward). Oder das AI Explained Video zum Thema: https://youtu.be/ZJbu3NEPJN0?si=52rDEQyVV-8ipyEb
Kostenlos sind die Anfragen auf 16 alle 3 Stunden begrenzt (wenn ich das auf Discord richtig gelesen habe). Vision und Audio sind eigentlich ziemlich krass ... wenn ich das mal so "wissenschaftlich" ausdrücken darf. :)
Liebe Grüße Christopher und Gerrit
_______________________________________________ Dhd-ag-agki mailing list [email protected] To unsubscribe send an email [email protected]
-- Prof. Dr. Patrick Sahle <http://patrick-sahle.de> Bergische Universität Wuppertal <https://www.uni-wuppertal.de/> - Lehrstuhl für Digital Humanities - Büro: L 12.22 - ☎︎ +49-202-439-5273 Mitglied des Institut für Dokumentologie und Editorik <http://www.i-d-e.de> e.V. [email protected] <https://mastodon.social/@[email protected]> - @patrick_sahle <https://twitter.com/patrick_sahle> - @DH_BUW <https://twitter.com/DH_BUW> - @ideinfo <https://twitter.com/ideinfo>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Lieber Patrick, aus meiner Sicht funktioniert es mit dem Text in den Bildern etwas besser, ist aber immer noch nicht brauchbar, wie du richtig sagst. Es sollte aber schon eine DALL-E Version sein. Zwei Gedanken: * Es ist einfach etwas besser, wenn der Text in den Bildern generiert wird. Aber eben nicht wirklich brauchbar, wenn auch besser als früher. * Das ist, wie andere multimodale Funktionen, etwas, das erst in den nächsten Wochen kommen wird. Viele User:innen sind übrigens überrascht, dass nicht alle angekündigten Funktionen sofort nutzbar sind ... super seriöse Firma ... ^^ Und wenn ich schon dabei bin, was ich wirklich spannend finde: Man kann jetzt in Gemini Advanced (kostenpflichtige Version) das 1 Million Token Context Window benutzen. Habe ich heute schon ausprobiert. Bis 700 Seiten im Context Window zu haben ist wirklich beeindruckend. lg Christopher Am 14.05.2024 um 11:33 schrieb Patrick Sahle:
Lieber Christopher, liebe alle,
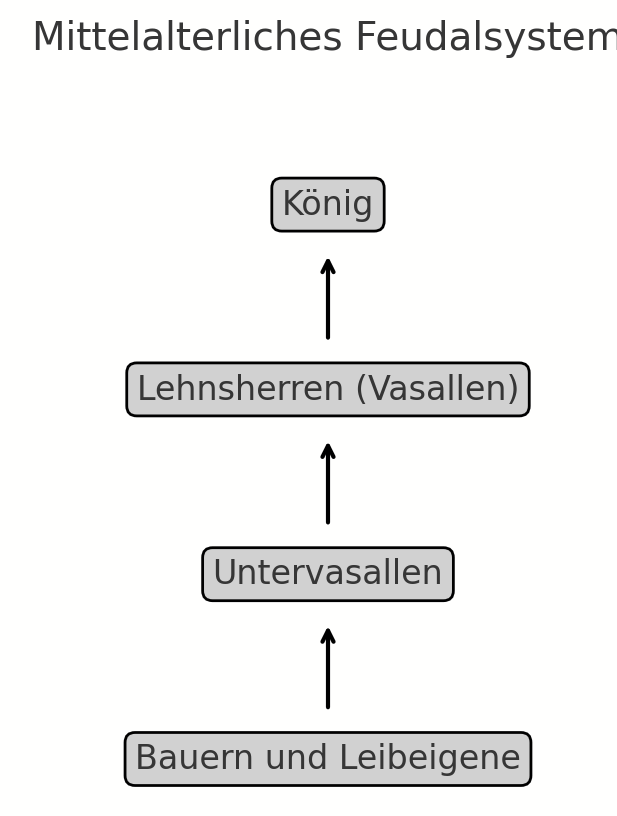
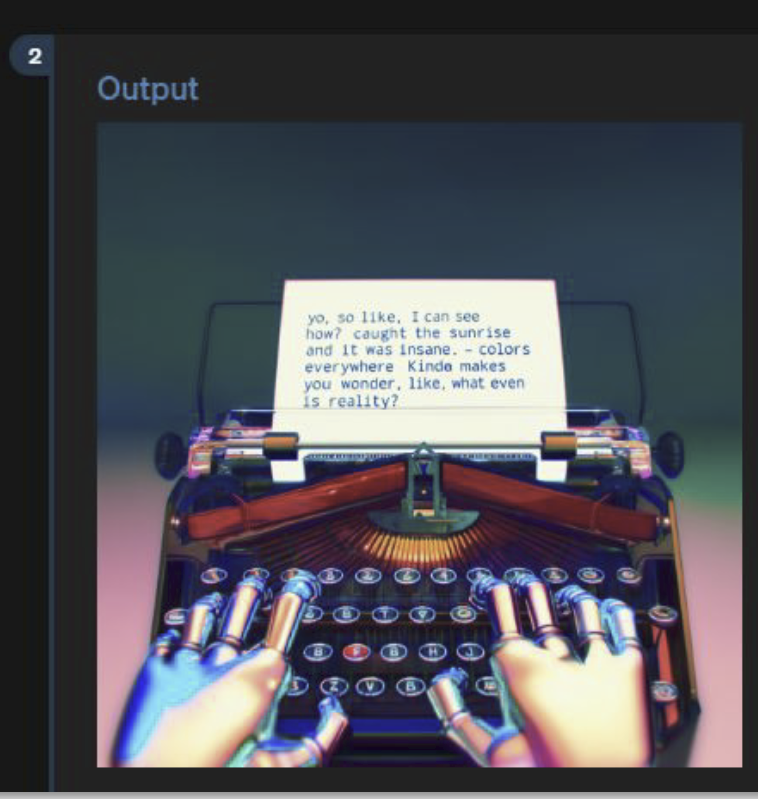
Danke auch für das update zu GPT4o. Mich hat da besonders der Punkt "Gute Texterzeugung in Bildern" interessiert, denn das war bisher ja eine doofe Schwäche. Und in deinem Beispiel auf der Folie ist ja auch korrekter Text. Jetzt habe ich das in GPT4o selbst getestet und kann das nicht bestätigen.
Es macht zwar ein "Diagramm" mit korrektem Text, aber bei "Bildern" scheint es immer noch von DALL-E abhängig zu sein (?), das dann wieder alles verhunzt?
Auf Rückfrage bestätigt GPT, dass das zweite von DALL-E gekommen sei und behauptet GPT, dass das erste python+matplotlib sei.
Deshalb die Frage: wie wird wohl das Beispiel auf deiner Folie erzeugt worden sein? Das ist dann doch nicht DALL-E? Weiß jemand genaueres?
Vermutlich ist es doch einfach DALL-E. Ich habe den Prompt für das Beispiel nochmal in einen frischen Chat kopiert und bekomme dieses wie üblich falsche Ergebnis:
Viele Grüße, Patrick
Am 14.05.2024 um 10:10 schrieb Christopher Pollin:
Liebe Liste,
eine Erinnerung für das Webinar zu *GitHub Copilot*. *Sebastian Schiller-Stoff* wird zeigen, wie er Copilot in seiner täglichen Arbeit als Softwareentwickler einsetzt.
* Morgen: 15.05. (11:30 bis 12:30) * Zoom: https://uni-graz.zoom.us/j/69588616456?pwd=OFJsYzc0TXFXM3draHI2M2ZGSDlSUT09
Und noch zwei interessante Infos:
*Claude 3 ist nun auch in Europa verfügbar*: https://claude.ai
Aber wahrscheinlich zu spät, denn OpenAI hat gestern *GPT-4o* veröffentlicht. Das ist nämlich kostenlos! Anbei ein kleines und schnelles Slide-Deck, wo ich alle Infos über GPT-4o gesammelt habe, soweit ich sie aufbereitet habe (#AISteward). Oder das AI Explained Video zum Thema: https://youtu.be/ZJbu3NEPJN0?si=52rDEQyVV-8ipyEb
Kostenlos sind die Anfragen auf 16 alle 3 Stunden begrenzt (wenn ich das auf Discord richtig gelesen habe). Vision und Audio sind eigentlich ziemlich krass ... wenn ich das mal so "wissenschaftlich" ausdrücken darf. :)
Liebe Grüße Christopher und Gerrit
_______________________________________________ Dhd-ag-agki mailing list [email protected] To unsubscribe send an email [email protected]
-- Prof. Dr. Patrick Sahle <http://patrick-sahle.de> Bergische Universität Wuppertal <https://www.uni-wuppertal.de/> - Lehrstuhl für Digital Humanities - Büro: L 12.22 - ☎︎ +49-202-439-5273 Mitglied des Institut für Dokumentologie und Editorik <http://www.i-d-e.de> e.V. [email protected] <https://mastodon.social/@[email protected]> - @patrick_sahle <https://twitter.com/patrick_sahle> - @DH_BUW <https://twitter.com/DH_BUW> - @ideinfo <https://twitter.com/ideinfo>
_______________________________________________ Dhd-ag-agki mailing list [email protected] To unsubscribe send an email [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Lieber Christopher, lieber Patrick, nur ein schneller Nebengedanke ... Die Generierung von Texten verbessert sich momentan zunehmend von Version zu Version (und von Beta der Zwischenversion zu Zwischenversion der Beta) auch bei z.B. Midjourney. Mit etwas Geduld und/oder nicht allzu komplexen Aufgaben hat man ja oft doch schon recht schnell ein gutes Ergebnis. Trotzdem geht es momentan oft immer noch schneller, die Textbestandteile in der Bildbearbeitung nachträglich zu optimieren. Die One-Shot-Trefferquote nimmt jedoch deutlich zu. In mancher Hinsicht ist es da vielleicht sogar ein Vorteil, wenn das derzeitige Problem weiterhin bei Dall-E hängt. Optimierungen bei Dall-E sollten in kürzeren Zeitabständen möglich sein, als Verbesserungen des Gesamtprodukts. ... und ja, auch ich bin enttäuscht, dass ich 4o noch nicht zum Singen bringen konnte! lg Thomas Dr. Thomas Jäger Abteilungsleitung Digital Humanities https://pagina-dh.de https://www.instagram.com/paginadh/ https://twitter.com/paginaDH E-Mail:[email protected] Telefon: (07071) 9876-21 pagina GmbH - Publikationstechnologien Herrenberger Straße 51 | 72070 Tübingen www.pagina.gmbh |www.parsx.de Handelsregister Stuttgart - HRB 380249 Geschäftsführer: Tobias Ott Am 15.05.2024 um 15:24 schrieb Christopher Pollin:
Lieber Patrick,
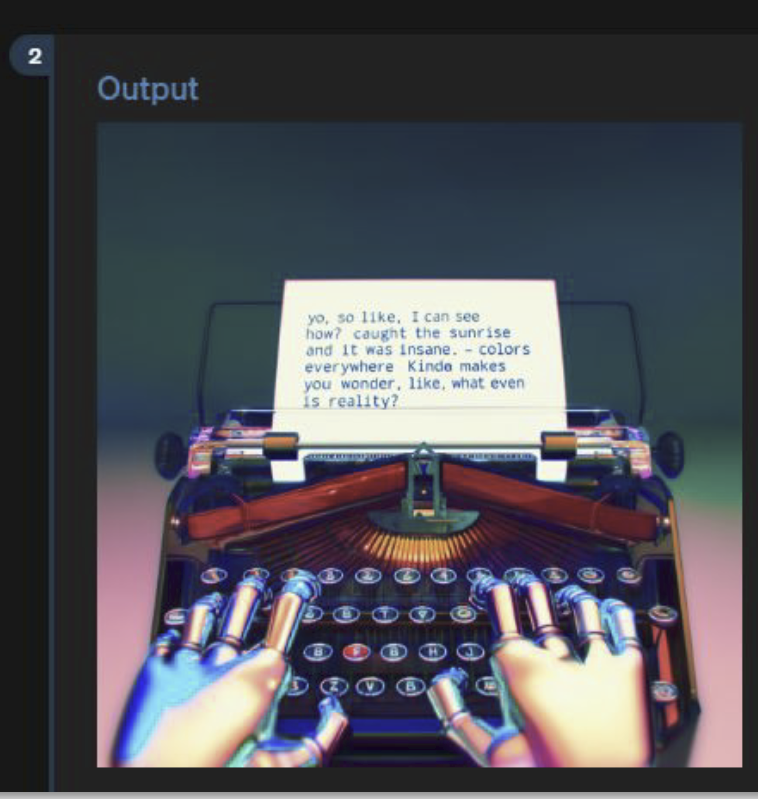
aus meiner Sicht funktioniert es mit dem Text in den Bildern etwas besser, ist aber immer noch nicht brauchbar, wie du richtig sagst. Es sollte aber schon eine DALL-E Version sein.
Zwei Gedanken:
* Es ist einfach etwas besser, wenn der Text in den Bildern generiert wird. Aber eben nicht wirklich brauchbar, wenn auch besser als früher. * Das ist, wie andere multimodale Funktionen, etwas, das erst in den nächsten Wochen kommen wird. Viele User:innen sind übrigens überrascht, dass nicht alle angekündigten Funktionen sofort nutzbar sind ... super seriöse Firma ... ^^
Und wenn ich schon dabei bin, was ich wirklich spannend finde: Man kann jetzt in Gemini Advanced (kostenpflichtige Version) das 1 Million Token Context Window benutzen. Habe ich heute schon ausprobiert. Bis 700 Seiten im Context Window zu haben ist wirklich beeindruckend.
lg
Christopher
Am 14.05.2024 um 11:33 schrieb Patrick Sahle:
Lieber Christopher, liebe alle,
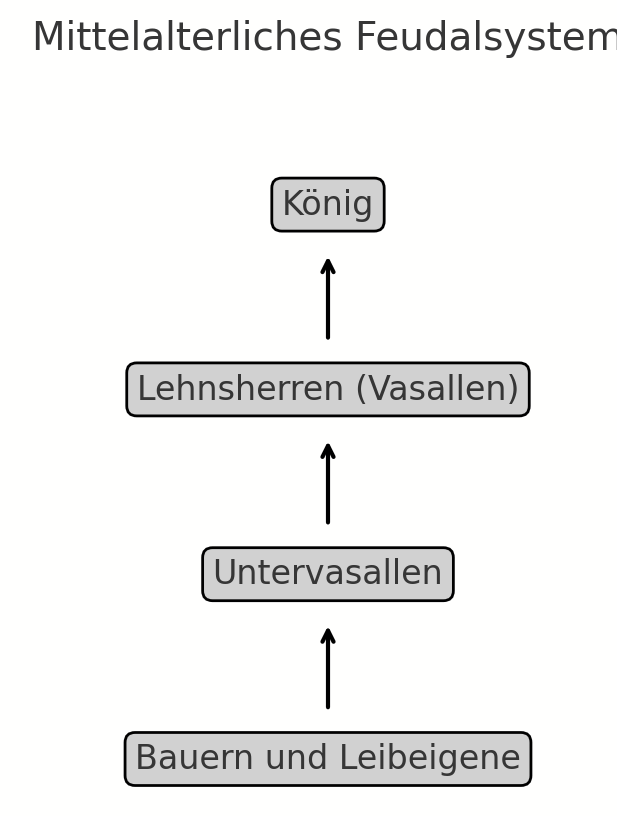
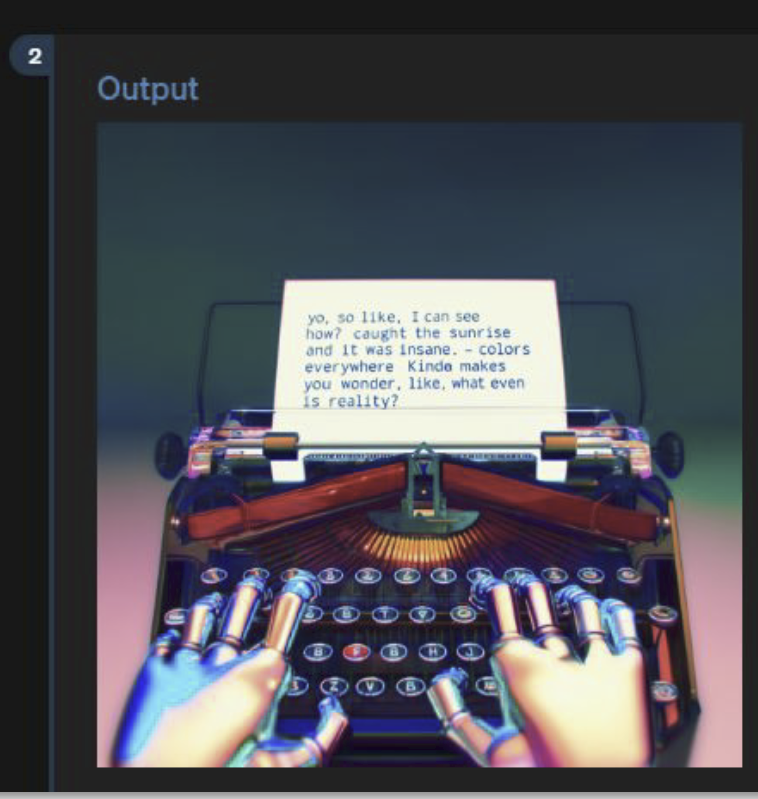
Danke auch für das update zu GPT4o. Mich hat da besonders der Punkt "Gute Texterzeugung in Bildern" interessiert, denn das war bisher ja eine doofe Schwäche. Und in deinem Beispiel auf der Folie ist ja auch korrekter Text. Jetzt habe ich das in GPT4o selbst getestet und kann das nicht bestätigen.
Es macht zwar ein "Diagramm" mit korrektem Text, aber bei "Bildern" scheint es immer noch von DALL-E abhängig zu sein (?), das dann wieder alles verhunzt?
Auf Rückfrage bestätigt GPT, dass das zweite von DALL-E gekommen sei und behauptet GPT, dass das erste python+matplotlib sei.
Deshalb die Frage: wie wird wohl das Beispiel auf deiner Folie erzeugt worden sein? Das ist dann doch nicht DALL-E? Weiß jemand genaueres?
Vermutlich ist es doch einfach DALL-E. Ich habe den Prompt für das Beispiel nochmal in einen frischen Chat kopiert und bekomme dieses wie üblich falsche Ergebnis:
Viele Grüße, Patrick
Am 14.05.2024 um 10:10 schrieb Christopher Pollin:
Liebe Liste,
eine Erinnerung für das Webinar zu *GitHub Copilot*. *Sebastian Schiller-Stoff* wird zeigen, wie er Copilot in seiner täglichen Arbeit als Softwareentwickler einsetzt.
* Morgen: 15.05. (11:30 bis 12:30) * Zoom: https://uni-graz.zoom.us/j/69588616456?pwd=OFJsYzc0TXFXM3draHI2M2ZGSDlSUT09
Und noch zwei interessante Infos:
*Claude 3 ist nun auch in Europa verfügbar*: https://claude.ai
Aber wahrscheinlich zu spät, denn OpenAI hat gestern *GPT-4o* veröffentlicht. Das ist nämlich kostenlos! Anbei ein kleines und schnelles Slide-Deck, wo ich alle Infos über GPT-4o gesammelt habe, soweit ich sie aufbereitet habe (#AISteward). Oder das AI Explained Video zum Thema: https://youtu.be/ZJbu3NEPJN0?si=52rDEQyVV-8ipyEb
Kostenlos sind die Anfragen auf 16 alle 3 Stunden begrenzt (wenn ich das auf Discord richtig gelesen habe). Vision und Audio sind eigentlich ziemlich krass ... wenn ich das mal so "wissenschaftlich" ausdrücken darf. :)
Liebe Grüße Christopher und Gerrit
_______________________________________________ Dhd-ag-agki mailing list [email protected] To unsubscribe send an email [email protected]
-- Prof. Dr. Patrick Sahle <http://patrick-sahle.de> Bergische Universität Wuppertal <https://www.uni-wuppertal.de/> - Lehrstuhl für Digital Humanities - Büro: L 12.22 - ☎︎ +49-202-439-5273 Mitglied des Institut für Dokumentologie und Editorik <http://www.i-d-e.de> e.V. [email protected] <https://mastodon.social/@[email protected]> - @patrick_sahle <https://twitter.com/patrick_sahle> - @DH_BUW <https://twitter.com/DH_BUW> - @ideinfo <https://twitter.com/ideinfo>
_______________________________________________ Dhd-ag-agki mailing list [email protected] To unsubscribe send an email [email protected]
_______________________________________________ Dhd-ag-agki mailing list [email protected] To unsubscribe send an email [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Hallo zusammen, hier eine Zusammenfassung einiger Vermutungen aus dem Netz: Im Moment scheint das öffentlich verfügbare gpt-4o vor allem ein wrapper für gpt-4 zu sein, der mehr Inputformate akzeptiert, aber immer noch Dall-E für den output verwendet. Eigentlich ist das noch kein marktreifes Produkt, aber das wahre gpt-4o soll multimodal "from the ground up" zu sein. Also kein Sprachmodell, das dann ein Bildmodell anpingt, um ein Bild zu generieren, sondern von vornherein auf Bild, Text, Audio usw. zugleich trainiert worden ist. Hier ein auf Twitter veröffentlichtes Beispiel: Image Wenn diese Vermutungen stimmen, dan ist GPT-4o ein autoregressives Modell mit mehreren parallelen Tokenizern. Dall-E, MidJourney, Stable Diffusion sind als Bildgeneratoren alles Diffusionsmodelle, d.h. eigentlich momentan inkompatibel mit der Architektur von Sprachmodellen. LLMs - so die sich langsam durchsetzende Entdeckung - einigermaßen logisch schlussfolgern. Das ist etwas, was den Diffusionsmodellen bei Bildern nicht gelingt, und was wohl am Ende doch mit den Eigenschaften menschlicher Sprache an sich zu tun hat. Deshalb erzeugen die Diffusionsmodelle Hände mit 4 oder 7 Fingern und kümmern sich nicht um andere logische Zusammenhänge im Bild. Ein Modell, das a priori multimodal trainiert wurde, sollte dagegen die Logik-Kapazitäten seiner Sprachanteile auf Bildgenerierung anwenden können. Und vermutlich ist GPT-4o - sobald es aus der Alphaphase raus ist - so ein Modell. Viele Grüße Thomas PS: Manchen ist ja logisches Schlussfolgern an sich egal: CDN media Am 15.05.24 um 15:24 schrieb Christopher Pollin:
Lieber Patrick,
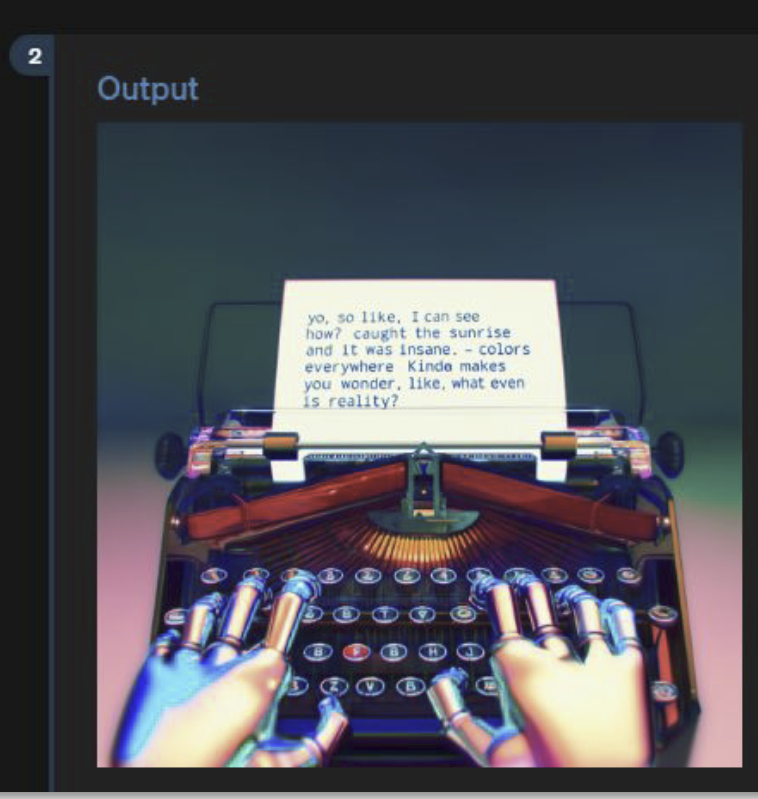
aus meiner Sicht funktioniert es mit dem Text in den Bildern etwas besser, ist aber immer noch nicht brauchbar, wie du richtig sagst. Es sollte aber schon eine DALL-E Version sein.
Zwei Gedanken:
* Es ist einfach etwas besser, wenn der Text in den Bildern generiert wird. Aber eben nicht wirklich brauchbar, wenn auch besser als früher. * Das ist, wie andere multimodale Funktionen, etwas, das erst in den nächsten Wochen kommen wird. Viele User:innen sind übrigens überrascht, dass nicht alle angekündigten Funktionen sofort nutzbar sind ... super seriöse Firma ... ^^
Und wenn ich schon dabei bin, was ich wirklich spannend finde: Man kann jetzt in Gemini Advanced (kostenpflichtige Version) das 1 Million Token Context Window benutzen. Habe ich heute schon ausprobiert. Bis 700 Seiten im Context Window zu haben ist wirklich beeindruckend.
lg
Christopher
Am 14.05.2024 um 11:33 schrieb Patrick Sahle:
Lieber Christopher, liebe alle,
Danke auch für das update zu GPT4o. Mich hat da besonders der Punkt "Gute Texterzeugung in Bildern" interessiert, denn das war bisher ja eine doofe Schwäche. Und in deinem Beispiel auf der Folie ist ja auch korrekter Text. Jetzt habe ich das in GPT4o selbst getestet und kann das nicht bestätigen.
Es macht zwar ein "Diagramm" mit korrektem Text, aber bei "Bildern" scheint es immer noch von DALL-E abhängig zu sein (?), das dann wieder alles verhunzt?
Auf Rückfrage bestätigt GPT, dass das zweite von DALL-E gekommen sei und behauptet GPT, dass das erste python+matplotlib sei.
Deshalb die Frage: wie wird wohl das Beispiel auf deiner Folie erzeugt worden sein? Das ist dann doch nicht DALL-E? Weiß jemand genaueres?
Vermutlich ist es doch einfach DALL-E. Ich habe den Prompt für das Beispiel nochmal in einen frischen Chat kopiert und bekomme dieses wie üblich falsche Ergebnis:
Viele Grüße, Patrick
Am 14.05.2024 um 10:10 schrieb Christopher Pollin:
Liebe Liste,
eine Erinnerung für das Webinar zu *GitHub Copilot*. *Sebastian Schiller-Stoff* wird zeigen, wie er Copilot in seiner täglichen Arbeit als Softwareentwickler einsetzt.
* Morgen: 15.05. (11:30 bis 12:30) * Zoom: https://uni-graz.zoom.us/j/69588616456?pwd=OFJsYzc0TXFXM3draHI2M2ZGSDlSUT09
Und noch zwei interessante Infos:
*Claude 3 ist nun auch in Europa verfügbar*: https://claude.ai
Aber wahrscheinlich zu spät, denn OpenAI hat gestern *GPT-4o* veröffentlicht. Das ist nämlich kostenlos! Anbei ein kleines und schnelles Slide-Deck, wo ich alle Infos über GPT-4o gesammelt habe, soweit ich sie aufbereitet habe (#AISteward). Oder das AI Explained Video zum Thema: https://youtu.be/ZJbu3NEPJN0?si=52rDEQyVV-8ipyEb
Kostenlos sind die Anfragen auf 16 alle 3 Stunden begrenzt (wenn ich das auf Discord richtig gelesen habe). Vision und Audio sind eigentlich ziemlich krass ... wenn ich das mal so "wissenschaftlich" ausdrücken darf. :)
Liebe Grüße Christopher und Gerrit
_______________________________________________ Dhd-ag-agki mailing list [email protected] To unsubscribe send an email [email protected]
-- Prof. Dr. Patrick Sahle <http://patrick-sahle.de> Bergische Universität Wuppertal <https://www.uni-wuppertal.de/> - Lehrstuhl für Digital Humanities - Büro: L 12.22 - ☎︎ +49-202-439-5273 Mitglied des Institut für Dokumentologie und Editorik <http://www.i-d-e.de> e.V. [email protected] <https://mastodon.social/@[email protected]> - @patrick_sahle <https://twitter.com/patrick_sahle> - @DH_BUW <https://twitter.com/DH_BUW> - @ideinfo <https://twitter.com/ideinfo>
_______________________________________________ Dhd-ag-agki mailing list [email protected] To unsubscribe send an email [email protected]
_______________________________________________ Dhd-ag-agki mailing list [email protected] To unsubscribe send an email [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
participants (4)
-
 Christopher Pollin
Christopher Pollin -
 Patrick Sahle
Patrick Sahle -
 Thomas Jäger
Thomas Jäger -
 Thomas Renkert
Thomas Renkert